- 一、背景
- 二、思路
- 三、实现
- 1. 数据写入Dolphin
- 2. 读取Dolphin文件
- 3. 跳读
- 4. 序列化
一、背景
Linkis面临将多种类型的数据存储到文件里面的需求,如:将Hive表数据存储到文件,并希望能保存字段的类型、列名和comment等元数据信息。
现有的文件存储方案一般只支持特定的数据类型进行存储,如:ORC支持数据表但是不支持非结构化数据的保存。
同时,支持保存特殊字符,也是促使我们定义新文件格式的原因。如:textFile中如果某个字段有换行符等特殊字符,解析读取时会导致内容异常。
最后,如果文件内容过大,Linkis通常希望提供分页功能,现有的文件存储方案只支持跳过多少字节,不支持跳过多少行,或者只读取文件中的某一行。
二、思路
Linkis定义了一种存储多种数据类型的文件存储格式Dolphin文件。
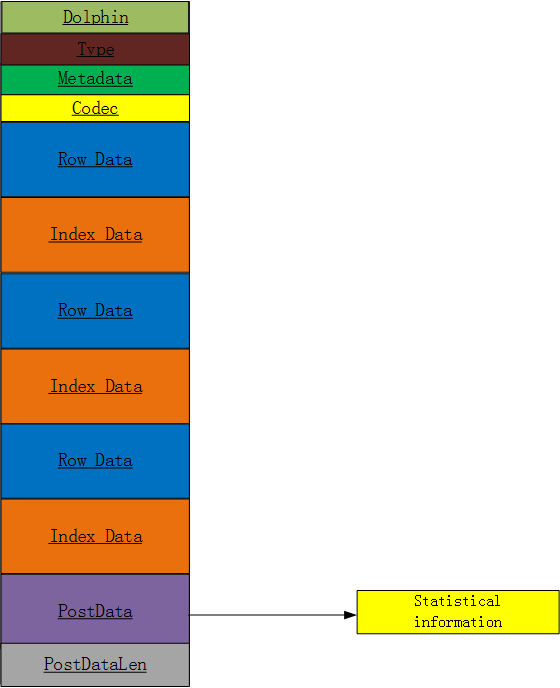
Dolphin的文件结构如上图所示:
文件开头存储Dolphin标识,用于区分是否该文件是Dolphin文件
Metadata:内容元数据信息
index Data: 行长索引
RowData: 行数据。
RowData存储了一行数据,如:存储了表格某行的数据,包括行数据长度和行数据的Byte信息。
PostData: 文件基本信息
PostDataLen:基本信息长度
其中PostData是文件的基本信息主要由:
type:存储内容的类型
Codec:编码格式
Statistical information:文件内容统计信息包括行数,最大最小值等。
三、实现
Dolphin文件的读入和写入的具体流程如下图:
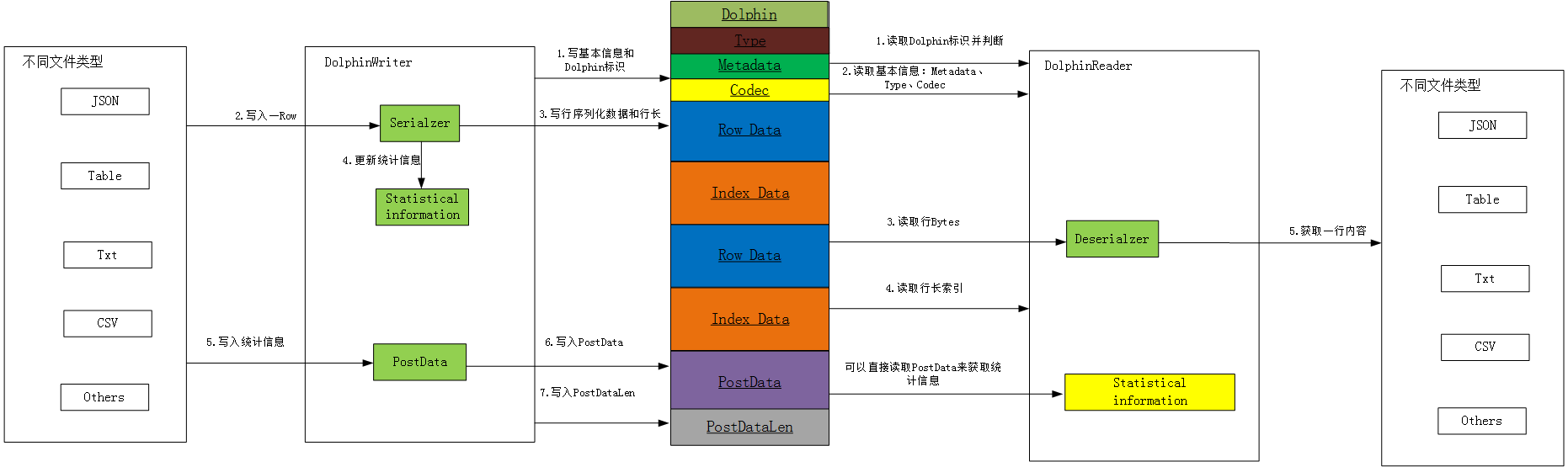
1. 数据写入Dolphin
用户需要将一种文件内容(比如:table)存储到Dolphin文件时步骤如下:
1、写入Dolphin文件标识
2、写入数据类型Type
3、通过序列化器(Serializer),写入Metadata(元数据)如table的列名,每列的类型,列注释等;
4、传入一行数据到DolphinWriter ,DolphinWriter通过序列化器(Serializer)序列化该行数据获得该行行长和序列化后的Bytes写入到Dolphin文件;
5、在写入该行数据后会更新统计信息(Statistical information),增加行记录数,更新每列最大最小值等;
6、DolphinWriter将统计信息,编码信息等组成PostData(基本信息)写入到Dolphin文件;
7、写入PostData的长度,完成写入操作。
2. 读取Dolphin文件
用户读取Dolphin文件内容步骤如下:
1、读取Dolphin文件标识,如果不是Dolphin文件则抛出异常;
2、如果用户只需要读取Statistical information,则读取PostData的长度,并依据该长度获取PostData。
通过PostData,将基本信息进行解析为对应的Type,Codec,MetaData,Statistical information。
返回,完成本次读取操作。
3、如果用户希望读取数据,则先读取数据类型Type。
4、读取Metadata信息,通过Type获取解序列化器(Deserializer),将读取的Bytes数据封装成MetaData
5、读取行长索引,并通过行长索引读取行Bytes。通过Type获取解序列化器(Deserializer),将Bytes转化为Record数据,将Record和MetaData封装RowData;
6、将读取的RowData行内容给到用户就完成整个读取。
3. 跳读
问:如何读取某一行?如何从多少行开始读?
答: 在写入一行时会先写入行长索引,这样在读取时用户可以通过行长索引进行索引读取和跳行读取;
4. 序列化
序列化器(Serializer)会将数据序列化为byte数组,解序列化器(Deserializer)会将byte数组解析为字符串数据,实现对特殊字符的正确读写;
序列化器(Serializer)和解序列化器(Deserializer)与类型(Type)是关联的,不同的数据类型可以定义不同的Serializer和Deserializer。
Dolphin提供了通用接口用于用户自定义实现对其他类型文件的支持。
