- 一、背景
- 二、思考
- 三、实现
- 1. 导出
- 2. 导入
一、背景
数据分析师或数据仓库员经常需要将数据从数据库导出到Excel等文件进行数据分析,或将数据导出为Excel提供给用户或合作商户。
而且,用户经常需要将CSV,Excel等数据文件和线上Hive数据库的数据进行联合分析,这个时候就需要将这些文件导入到Hive数据库。
对于银行等比较机密性的行业,数据导出时往往需要对导出的敏感字段如身份证,手机号进行脱敏处理。
二、思考
借助于Spark的分布式计算能力和支持连接多种数据源的DataSource。
三、实现
1. 导出
导出流程如下图所示:
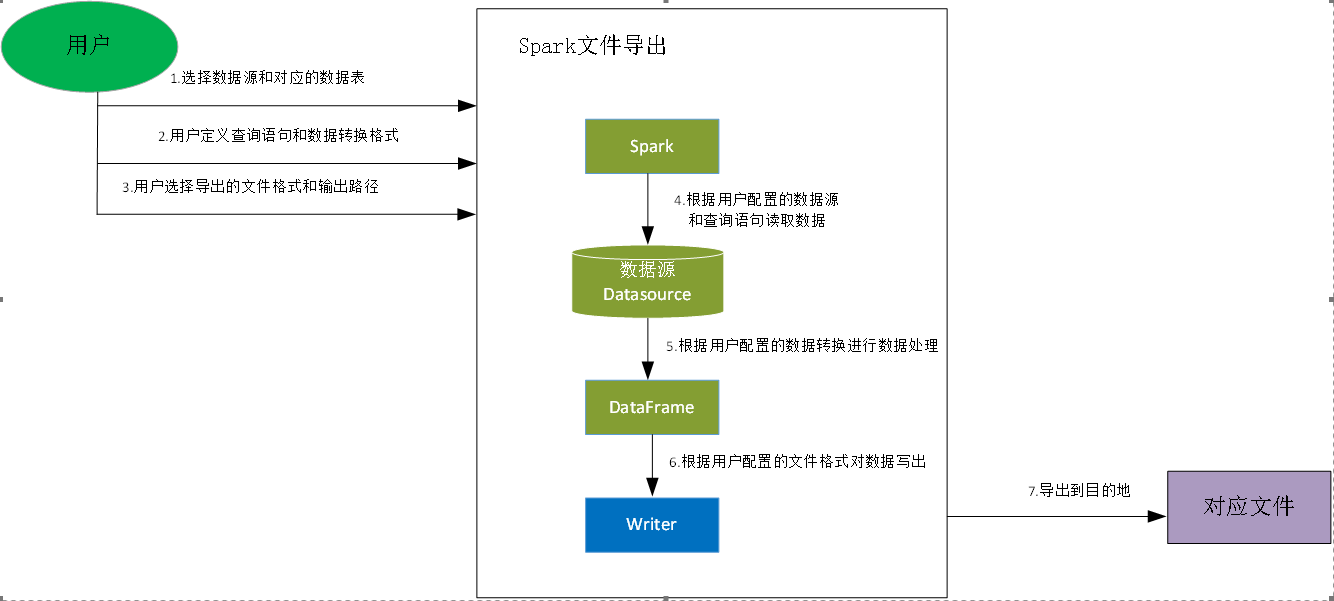
用户选择对应的数据源和对应需要导出的数据表如:Mysql库中的用户订单表;
用户定义从数据表需要导出的数据的查询语句,以及定义对指定的列进行的数据转换。
如:定义导出最近半年的订单表,并对用户信息进行脱敏处理;
用户选择需要导出的文件格式和输出路径,如:导出用户订单表为excel,路径为/home/username/orders.xlsx
Spark根据用户配置的数据源和表以及查询语句读取对应的数据,DataSource支持多种数据存储组件如:Hive,Mysql,Oracle,HDFS,Hbase,Mongodb等
接着根据用户配置的数据转换格式对数据进行处理为DataFrame
根据用户配置的文件格式类型获取对应的文件写出对象进行文件写入,如:支持Spark的Excel的文件写出对象。Writer支持多种文件格式如Excel,exce,Json
将对应的数据通过Writer写出到对应的目的地,如:/home/username/orders.xlsx。
2. 导入
导入流程如下:
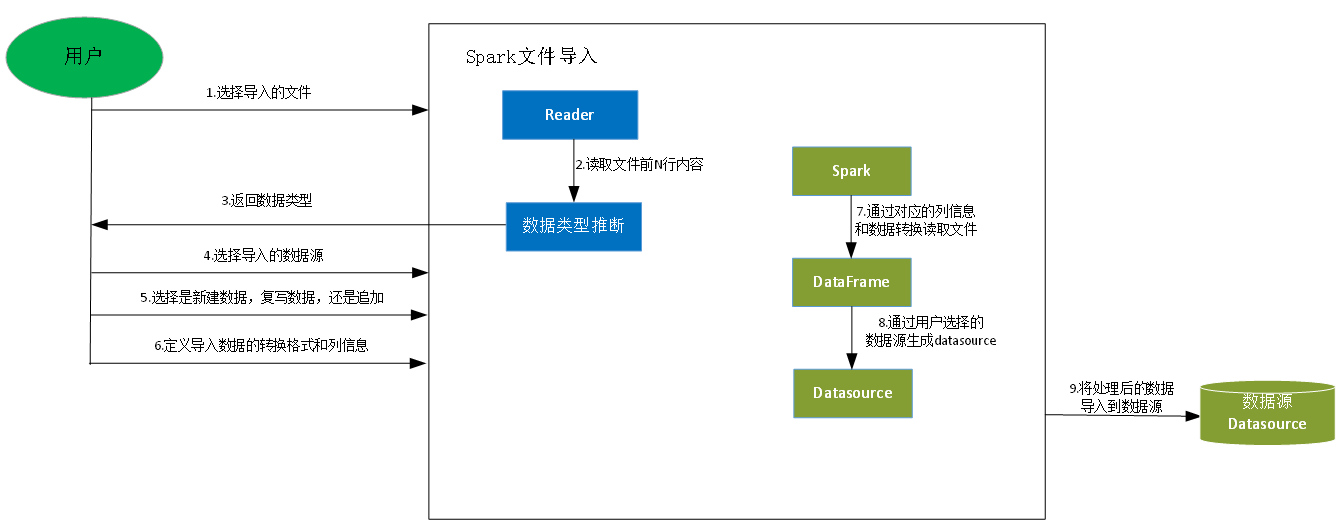
用户选择导出的文件,文件读入对象(Reader)会根据传入的文件进行读取:如:/home/username/orders.xlsx;
Reader读取前N行的内容用于数据类型推断,如读取10行。Reader支持多种文件格式的读取。
数据类型推断器通过传入的前10行进行数据类型判断,判断每一列的数据类型,判断方法为通过判断每一行的数据类型,并最终通过判断哪种类型出现的次数最多进行推断,并返回给用户。
如:user:String,orderId:Int;
用户选择需要导入的数据源,如:Mysql。导入的数据也支持选择多种;
用户选择树新建数据,或者复写数据,还是追加数据。如选择用户订单表,并选择数据追加;
用户定义数据导入的转换格式和导入的列信息,如:对用户信息进行解密
方案使用Spark并通过用户传入的数据转换给事和列信息进行文件读取为DataFrame;
通过用户选择的数据源生成对应的Datasource;
将处理后的DataFrame通过Datasource导入到对应的数据源,如:Mysql库中的用户订单表。
