- 监控工具
- top
- vmstat
- uptime
- ps 和 pstree
- free
- iostat
- sar
- mpstat
- numastat
- pmap
- netstat
- iptraf
- tcmpdump / ethereal
- nmon
- strace
- Proc文件系统
- KDE System Guard
- Gnome System Monitor
- 性能管理器
监控工具
- 监控工具
- top
- vmstat
- uptime
- ps and pstree
- free
- iostat
- sar
- mpstat
- numastat
- pmap
- netstat
- iptraf
- tcpdump / ethereal
- nmon
- strace
- Proc文件系统
- KDE System Guard
- Gnome System Monitor
- Capacity Manager
在本小节,我们将讨论常用监控工具。大多数Linux发行版中都携带了这些监控工具,你应该熟练掌握。
top
top命令会展示进程的实际活动。默认情况下,它会列出系统上所有cpu密集型任务,并且每5秒钟刷新一次列表。你可以对PID(数值),生存时间(最新的排最前面),时间(累计时间)以及常驻内存使用率和时间(进程启动开始占用cpu的时间)进行排序。
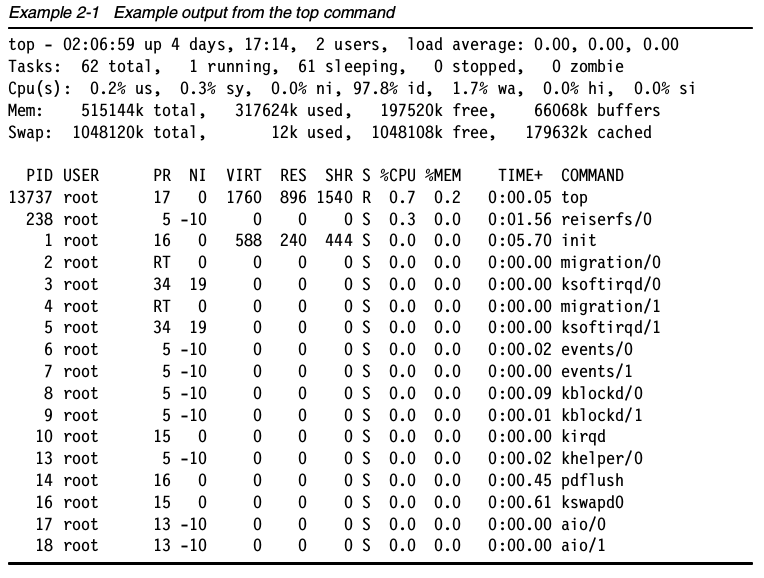
你也可以通过renice命令给进程设置一个优先级,如果一个进程挂了,或者占用太多CPU,你可以杀死(kill命令)这个进程。
输出中的各列:
- PID 进程号
- USER 进程所有者的名字。
- PRI 进程优先级
- NI nice级别
- SIZE 进程使用的内存(代码、数据和栈),kb单位
- RSS 物理RAM使用量,kb单位
- SHARE 和其它进程共享的内存,kb单位
- STAT 进程状态:S=睡眠,R=运行,T=停止或跟踪,D=不可中断的睡眠,Z=僵尸。请参考前文中的”进程状态“一节。
- %CPU CPU使用量。
- %MEM 物理内存用量
- TIME 进程使用的总CPU时间(从启动开始算)
COMMAND 进程的命令行启动命令(包括参数)
top命令还有如下几个常用的快捷键:t 关闭和开启进程汇总信息的展示
- m 关闭和开启内存信息的显示
- A 排序系统上各类资源的排序。对于快速找出系统上的性能问题的任务很有帮助。
- f 进入top的交互配置模式,对于给top设置特定的进程很有用。
- o 让你交互的选择top的排序。
- r 使用renice命令
- k 使用kill命令
vmstat
vmstat显示关于进程,内存,页,块I/O,traps和CPU的信息。vmstat既可以展示平均值,也可以是实时数据。通过提供采样频率和采样时间就可以开启vmstat的采样模式。
注意:考虑到采样模式中的短时高峰情况,把采样频率设置为一个较低的值可以避免这样的问题。
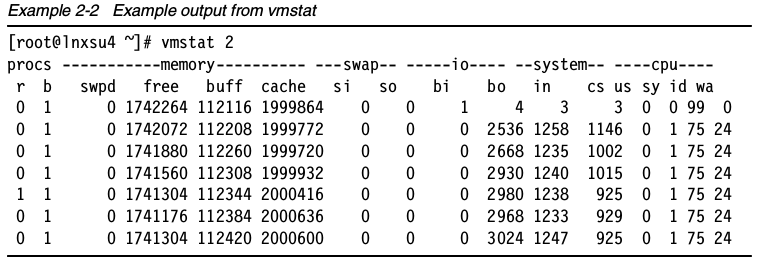
注意:第一行展示了从上次重启之后的平均值,所以应该屏蔽掉。
各列的含义如下:
- 进程
r:等待执行时间的进程数
b:在不可中断睡眠中的进程数
- 内存
swpd:已使用的虚拟内存量
free:空闲内存量
buff:作为缓冲的内存
cache:作缓存的内存
- Swap
si:从交换分区写到内存的量
so:从内存写到交换分区的大小
- IO
bi:发往块设备的数目(blocks/s)
bo:从块设备接收的块数目 (blocks/s)
- System
in:每秒钟的中断次数,包括时钟
cs:每秒的上下文切换次数
- CPU(总CPU时间的百分比):
us:运行非内核代码的时间(用户时间,包括nice时间)
sy:运行内核代码的时间(系统时间)
id:空闲时间,早先的Linux2.5.41版本,包含了I/O等待时间
wa:等待IO的时间,早先的Linux2.5.41版本,这个值为0
vmstat支持很多的命令行参数,vmstat的man手册中写的很详细。其中有如下常用的几个:
- -m 显示内核的内存使用(slabs)
- -a 显示活动和非活动的内存页
- -n 只显示一个标题行,如果vmstat运行在采样模式,并且使用输出到管道和文件的时候,这选项很有用。(例如,root# vmstat -n 2 10 间隔2秒采样一次,共收集10次数据)当使用-p {分区} 标志的时候,vmstat会显示I/O的统计。
uptime
uptime 命令可以用来查看服务器运行了多长时间,有多少用户登录在服务器上,以及服务器的平均负载。分别展示过去1分钟、5分钟和15分钟的系统瓶颈负载值。
平均负载最理想的值是1,意味着每个进程可以直接使用CPU,没有发生CPU周期丢失。不同系统的负载有很大差别。对单处理器工作站来说,1或2的负载值是勉强可以接受的,而在多处理器服务器上,平均负载为8或者10的时候,系统依旧运行良好。
使用uptime或许可以找出服务器或网络的问题。例如,当网络服务运行不佳时,你就可以用uptime命令查看系统负载情况。如果负载不高,问题可能出现在你的网络中,而不是服务器系统上。
小提示:你可以使用w替代uptime。w也可以查看当前登录系统的用户,以及他们在做什么。

ps 和 pstree
在系统分析中,ps和pstree是最基础的命令,ps有三种不同的命令选项,UNIX、BSD和GNU风格。我们来看看GNU风格的ps选项。
ps命令展示所有进程列表。top命令展示了进程活动,而且ps显示的信息更加详细。ps所显示出来的进程数量取决于所使用的命令参数。简单的ps -A命令会列出所有的进程和他们各自的PID,我们可以使用PID做更多的事情。在使用pmap,renice等工具的时候,就需要用到PID。
在运行java应用的服务器上,使用ps -A命令可能一下子就把显示器全部占满了,很难清楚查看运行进程的完整列表。在这个情况下,pstree命令可能就会派上用场,它把运行进程以树形结构展示,把子进程合并展示(例如java线程)。pstree可以识别出原始进程。ps还有另外一个变种pgrep,也十分有用。

其它的命令选项:
- -e 所有进程,和-A一样
- -l 显示长格式
- -F 额外的全格式,包括参数和选项。
- -H 显示进程等级
- -L 显示线程,可能带有LWP和NLWP列
- -m 在进程后面显示线程
使用如下命令可以看到详细的进程信息:
ps -elFL

输出的字段含义:
- F 进程标志
- S 进程状态:S=睡眠,R=运行,T=停止或跟踪, D=不可中断的睡眠,Z=僵尸。
- UID 拥有进程的用户名字。
- PID 进程ID
- PPID 父进程ID
- LWP LWP号(light weight process,or thread,轻量级进程,或线程)。
- c 处理器使用的百分比。
- NLWP 进程中的lwps(线程)个数。
- PRI 进程优先级
- NI nice级别(进程是否通过nice改变优先级,见下文)
- ADDR 进程地址空间(例子中没展示)
- SZ 进程使用的内存大小(代码+数据+栈) ,单位kb。
- WCHAN 睡眠进程的内核函数名字,如果进程在运行,显示“-”,如果显示为“*”,则表示是多线程。
- RSS 驻留内存大小,任务所使用的非swap物理内存大小,单位是kb。
- PSR 分配给进程的处理器个数。
- STIME 命令开始时间
- TTY 终端
- TIME 进程从启动开始,使用CPU的总时间
- CMD 开启任务的命令(包含参数)
线程信息
可以使用ps -L选项看到进程信息: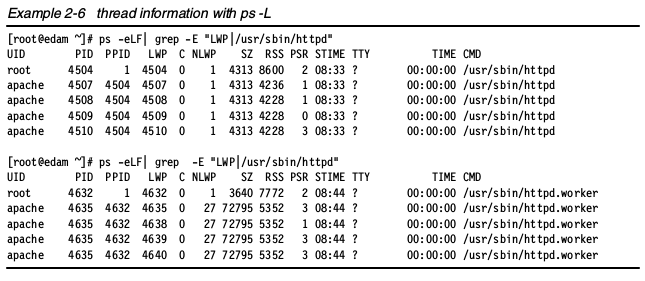
free
free命令显示了系统所有已用和可用内存(包括swap)量。也包括被内核使用的缓冲和缓存信息。
使用free命令的时候,记住Linux内存架构和虚拟内存管理器的工作方式。空闲内存是受限使用的,使用swap也不表示出现了内存瓶颈。下图展示了free命令的基本原理。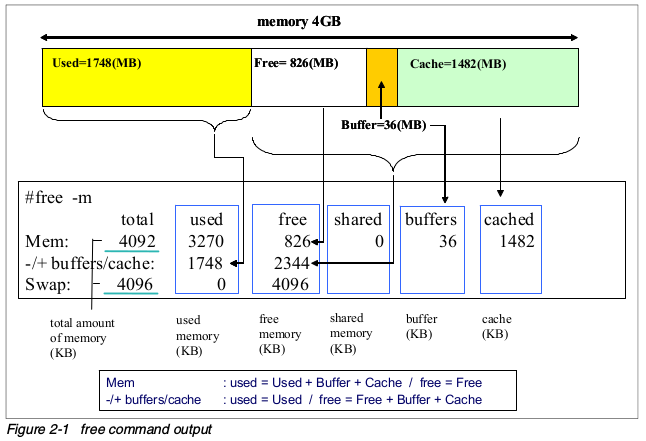 free命令的常用参数:
free命令的常用参数:
- -b,-k,-m,-g 以字节b,千字节kb,兆字节mb和吉字节gb为单位展示。
- -l 显示详细的高低内存统计
- -c 输出free的次数Memory used in a zone使用-l选项,可以看到在各个内存区域中使用的内存大小。
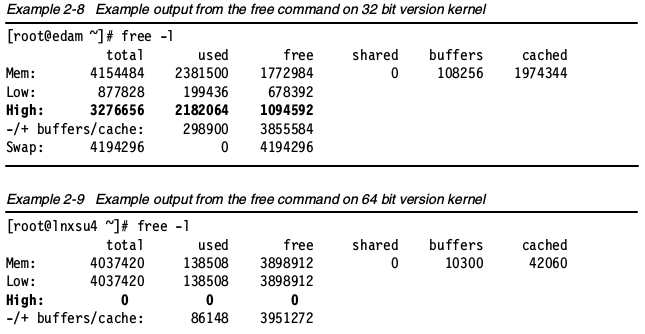
我们可以使用/proc/buddyinfo文件来决定每个区域中有多少个可用的内存块。每列数字意味着该列中可用的页数。在下面的例子中,在ZONE_DMA中有5块2^2_PAGE_SIZE 可用,在ZONE_DMS32中有16块2^3_PAGE_SIZE 可用。记住伙伴系统是如何分配内存页的。这些信息展示了内存中的分片,以及有多少页可以安全分配。
iostat
iostat命令显示从系统启动依赖的平均CPU时间(和uptime类似)。它会生成服务器磁盘子系统的活动报告:CPU和磁盘设备利用情况。使用iostat找出详细的I/O瓶颈,进行性能优化,详见“找到磁盘瓶颈”一节内容。iostat是sysstat包里的一个组件。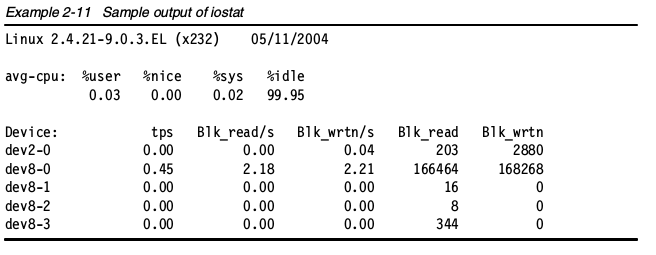 CPU使用报告有4个部分:
CPU使用报告有4个部分:
- %user 显示CPU在用户级执行应用程序所花时间的百分比。
- %nice 显示带有nice优先级的用户级程序占用的CPU时间百分比(详见“nice,renice一节”)。
- %sys 显示显示执行系统级(内核)任务所占用CPU时间的百分比。
%idle 显示CPU空闲的时间百分比。
设备使用报告包括如下部分:Device 块设备的名字
- tps 设备上的每秒传输次数(每秒的I/O请求数)。多个单I/O请求可以合成一个传输请求,因为每个传输请求的大小可以是不一样的。
- Blk_read/s,Blk_wrtn/s 每秒块读写显示了每秒从设备读或者写的数据。块也可以有不同的大小。常见的是1024,2048和4096字节,这是取决分区大小。例如,/dev/sda1的块大小可以计算:
dumpe2fs -h /dev/sda1 | grep -F "Block size"
输出内容可能如下:
dumpe2fs 1.34 (25-Jul-2003)
Block size: 1024
Blk_read,Blk_wrtn指示系统启动以来读和写的总块数。iostat有很多选项,在性能调试中最有用的是-x,它能显示扩展的统计信息。下面是输出样例。

rrqm/s,wrqm/s 每秒向设备发出的合并读写请求的数目。多个单一的读写请求可以合并为一个传输请求,因为传输请求的大小的可变的
r/s,w/s 设备上的每秒读/写请求次数。
- rsec/s,wsec/s 设备上每秒的读/写扇区数。
- rkB/s,wkB/s 每秒从设备上读取的kb数。
- avgrq-sz 向设备发出的请求的平均大小,显示为扇区。
- avgqu-sz 向设备发出的请求的平均队列长度
- await CPU执行系统任务的时间百分比
- svctm I/O请求的平均服务时间(毫秒)。
- %util I/O请求发出到设备的时间占用CPU的百分比(设备的带宽利用率)。该值接近100%时,设备能力几乎饱和。
在将磁盘子系统向访问模式调整时,计算平均I/O大小是是否有用的。如下命令使用iostat的-x和-d选项,用来展示我们感兴趣的磁盘: 上面的表格中,在kB_wrtn一列下显示了每秒写入12300.99KB数据到设备dasdc中。在w/s下显示,这些数据以2502.97次IO每秒的速度向磁盘发送。在上面的例子中,平均IO大小或者说平均请求大小显示在avgrq-sz下,是9.83块,块大小是512字节。异步写的平均I/O大小通常都很奇怪,大多数应用读写I/O都是4KB的倍数(例如,4KB,8KB,16KB,32KB等)。在上面例子的应用中,是4KB的随机写请求,但是iostat显示平均请求大小是4.915KB。这个差别是由文件系统导致的,即使执行随机写,有些I/O可以通过合并到一起,更加高效率的写入到磁盘子系统。
上面的表格中,在kB_wrtn一列下显示了每秒写入12300.99KB数据到设备dasdc中。在w/s下显示,这些数据以2502.97次IO每秒的速度向磁盘发送。在上面的例子中,平均IO大小或者说平均请求大小显示在avgrq-sz下,是9.83块,块大小是512字节。异步写的平均I/O大小通常都很奇怪,大多数应用读写I/O都是4KB的倍数(例如,4KB,8KB,16KB,32KB等)。在上面例子的应用中,是4KB的随机写请求,但是iostat显示平均请求大小是4.915KB。这个差别是由文件系统导致的,即使执行随机写,有些I/O可以通过合并到一起,更加高效率的写入到磁盘子系统。
当文件系统使用默认异步写模式时,iostat中只有平均请求大小是显示正确的。即使应用程序执行不同大小的写请求,Linux的I/O层将会合并,并且改变平均I/O的大小。
sar
使用sar命令可以收集、展示和保存系统信息。sar命令由三个部分组成:sar,显示数据,sa1和sa2,收集和存储数据。sar工具有很多选项,请多使用man手册确认用法。sar工具是sysstat包的一部分。因为有sa1和sa2,可以配置来收集和记录系统信息,用来以后分析。
小贴士:我们建议您尽可能的系统上运行sar,以防遇到性能问题的时候,手头可以有很详细的信息。而且,sar只消耗很少的系统资源。
在/etc/crontab中添加一行。记住,在系统上安装好sar后,cron默认每天运行sar(译者:不同的发行版可能有区别)。 sar记录的原始数据保存在/var/log/sa/下,每个文件代表月份下的每天。可以专门挑选工作日的日志记录来查看。例如,要显示21号的网络计数器,可以使用命令sar -n DEV -f sa21,然后使用管道传递给less。
sar记录的原始数据保存在/var/log/sa/下,每个文件代表月份下的每天。可以专门挑选工作日的日志记录来查看。例如,要显示21号的网络计数器,可以使用命令sar -n DEV -f sa21,然后使用管道传递给less。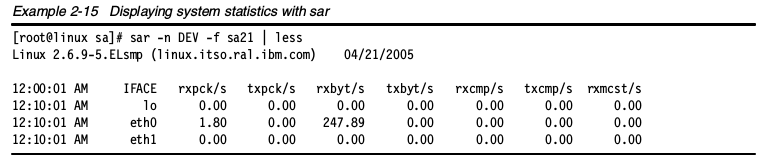 也可以使用sar命令行显示几乎实时的统计。
也可以使用sar命令行显示几乎实时的统计。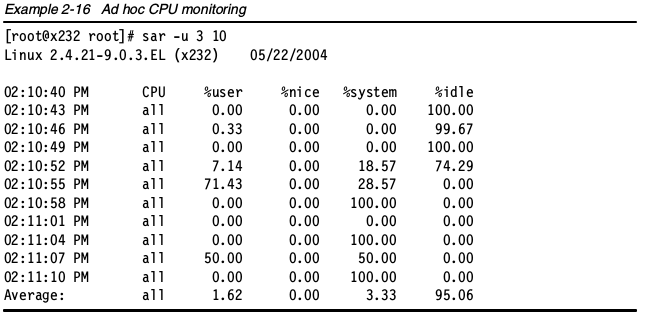 从收集的数据中,你可以看到详细的CPU使用信息(%nice,%user,%system,%idle),内存页,网络和I/O传输统计,进程创建、活动、块设备活动和每秒中断。
从收集的数据中,你可以看到详细的CPU使用信息(%nice,%user,%system,%idle),内存页,网络和I/O传输统计,进程创建、活动、块设备活动和每秒中断。
mpstat
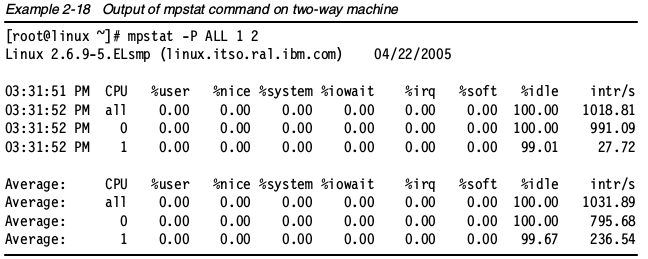
mpstat是一个可以展示多处理器服务器上每个可用CPU活动信息的命令。所有CPU的平均活动情况也会显示出来。mpstat也是sysstat包的一部分。mpstat工具可以全面展示系统或者CPU的统计信息。通过给mpstat传递采样频率和采样次数,可以模拟vmstat的使用。下图展示了通过mpstat -P ALL 来输出每个CPU的平均使用率。 把每个处理器的统计以每秒一次的频率输出三次,使用如下命令:
把每个处理器的统计以每秒一次的频率输出三次,使用如下命令:
mpstat -P ALL 1 2
 要获得mpstat的完整语法,使用:
要获得mpstat的完整语法,使用:
mpstat -?
numastat
在企业数据中心,非统一内存架构(Non-Uniform Memory Architecture ,NUMA)已经变成主流,例如IBM System x3950,然而,NUMA系统给调优带来了新的挑战。在NUMA出现之前,我们从来不需要关心内存的位置。幸好,企业Linux发行版为监测NUMA架构行为提供了工具。numastat命令提供本地和远程内存使用率和所有节点的整体内存配置。本地内存分配失败的信息在numa_miss一行展示,远程内存(shower memory)分配信息在numa_foregin一行展示。过度的使用远程内存会增加风险,可能导致整体性能下降。把进程绑定映射本地内存的节点会增加性能。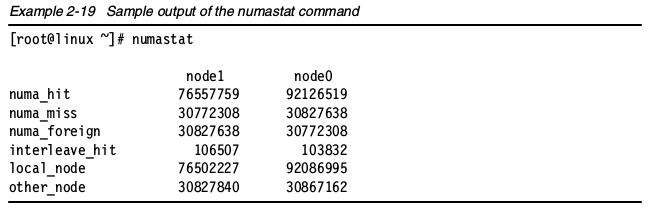
pmap
pmap命令会展示一个或多个进程正在使用的内存量。使用这一工具,你可以确定服务器上的哪一个进程正在分配内存,还有是否这部分内存导致了内存瓶颈。更多信息,使用pmap -d选项。
pmap -d <pid>
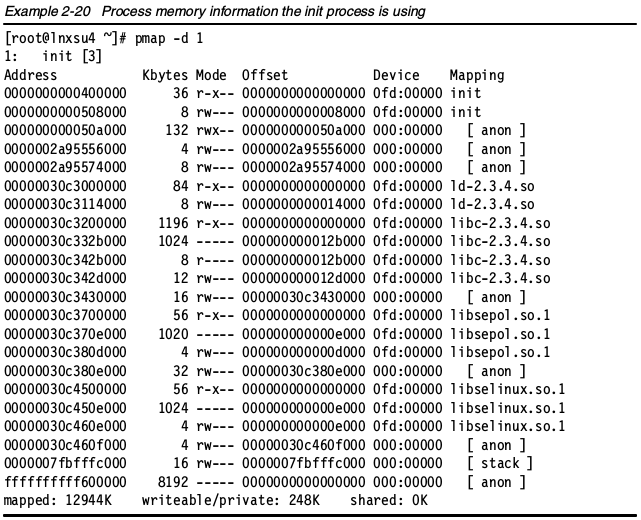 最后一行显示的信息最为有用:
最后一行显示的信息最为有用:
- mapped 该进程映射到文件的内存量。
- writable/private 该进程使用的私有地址空间。
- shared 该进程和其它进程共享的地址空间量。
你也可以查看存储信息的地址空间。在32位和64位系统上,pmap有些有趣的差别。使用如下命令查看完整的pmap语法:
pmap -?
netstat
netstat 是最常用的工具之一,如果你从事网络工作,你应该对这个命令很熟悉。它会展示网络相关的信息,例如socket使用,路由,接口,协议和其它网络统计。有如下的基础选项:
- -a 显示所有的socket信息
- -r 显示路由信息
- -i 显示网络接口统计
-s 显示网络协议统计
还有很多其它有用的选,请查阅man手册。如下的例子中展示了socket信息的样例。 Socket信息解释:
Socket信息解释: Proto socket使用的协议(tcp,udp,raw)。
- Recv-Q 表示收到的数据已经在本地接收缓冲,但是还有多少没有被进程取走,单位是字节。
- Send-Q 对方没有收到的数据或者说没有Ack的,还是本地缓冲区,单位字节。
- Local Address socket的本地地址和端口。除非使用—numeric(-n)选项,socket地址会被解释成主机名(FQDN),端口号会被转成相应的服务名字。
- Foreign Address 远端socket的端口和地址。
- State socket的状态。因为raw和UDP通常是没有状态的,所以这列可能是空白。
iptraf
iptraf监控和展示TCP/IP的实时流量。它可以根据各个session、接口、协议展示TCP/IP流量统计。iptraf组件是由iptraf包提供。iptraf给我们展示如下的报告:
- IP流量监控:通过TCP连接的网络流量统计
- 接口一般统计:网络接口流量统计
- 接口详细统计:根据端口的网络流量统计
- 统计分析:根据TCP/UDP端口和包大小的网络流量统计。
- 局域网统计:根据网络2层地址的网络流量统计。
下面是使用iptraf收集的几个报告。
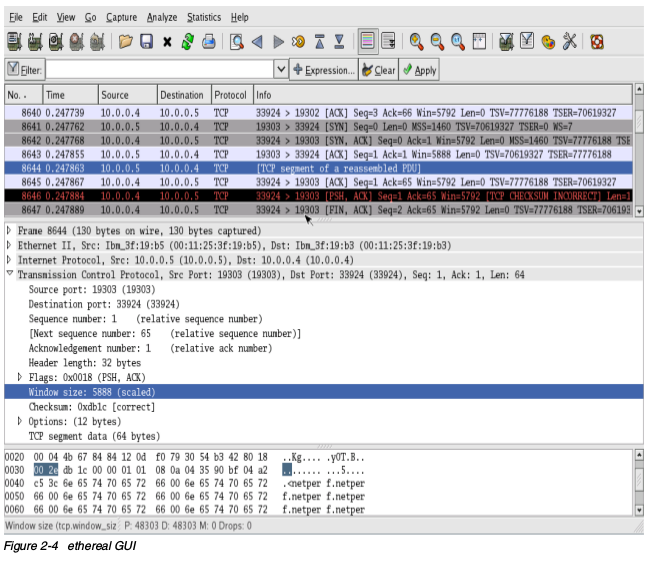
tcmpdump / ethereal
tcpdump和ethereal通常用来抓取和分析网络流量。这两个工具都会用到libpcap库来抓取包。在混杂模式下,它们会监控网卡上的所有流量,并且抓取所有网卡上收到的分片。为了抓取所有包,这些命令应该使用超级用户权限执行,以便开启网卡混杂模式。你可以使用这些工具来找到和网络相关的问题。可以发现TCP/IP重传,滑动窗口大小变化,名字解析问题、网络错误配置等。记住,这些工具只能监控所有到达网卡的分片,而不是所有的网络流量。tcpdumptcpdump是一个简单和强大的工具。它拥有基本的协议分析能力,可以获得网络上的大体情况。tcpdump可以使用很多选项和扩展表达式来过滤要抓取的包。入门可以看看如下的几个选项:
- -i 指定网络接口
- -e 打印数据链路层头
- -s 抓取每个包的字节
- -n 避免DNS解析
- -w 写入文件
- -r 从文件读取
-v,-vv,-vvv 详细输出
抓取过滤器的表达式:关键字: 源目主机,源目端口,tcp,udp,icmp,源目网络等等
联合逻辑使用 非 ('!'或者'not') 与 ('&&'或者'and') 或 ('||'或者'or')
十分有用的过滤表达式样例:DNS查询包
tcpdump -i eth0 'udp port 53'
- 目的主机为192.168.1.10的FTP传输和FTP数据会话
tcpdump -i eth0 'dst 192.168.1.10 and (port ftp or ftp-data)'
- 目标为192.168.2.253的HTTP会话
tcmpdump -ni eth0 'dst 192.168.2.253 and tcp and port 80'
- 到192.168.2.0/24子网的telnet会话(译者:例子中貌似是ssh会话)
tcmpdump -ni eth0 'dst net 192.168.2.0/24 and tcp and port 22'
- 抓取源目地址都不在192.168.1.0/24子网,并且带有TCP SYN或者TCP FIN标志(建立或者中断TCP连接)的数据。
tcpdump 'tcp[tcpflags] & (tcp-syn|tcp-fin)!=0 and not src and dst net 192.168.1.0/24'
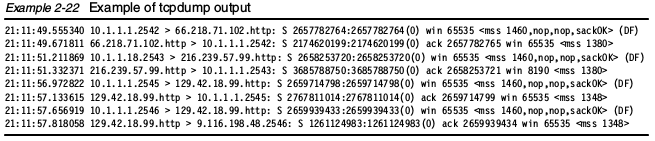 通过man手册可以获取更多tcpdump的用法。
通过man手册可以获取更多tcpdump的用法。
etherealethereal有和tcpdump相似的功能,但是更加复杂,并且拥有更高级的协议分析和报告能力。它还拥有一个GUI接口和ethereal命令行界面。和tcpdump类似,ethereal也可以使用过滤抓取,从而缩小抓取分片的范围。如下是一些常用的表达式。
- IP ip.version ==6 and ip.len > 1450 ip.addr == 129.111.0.0/16 ip.dst eq www.example.com and ip.src == 192.168.1.1 not ip.addr eq 192.168.4.1
- TCP/UDP tcp.port eq 22 tcp.port == 80 and ip.src == 192.168.2.1 tcp.dstport == 80 and (tcp.flags.syn == 1 or tcp.flags.fin == 1) tcp.srcport == 80 and (tcp.flags.syn == 1 and tcp.flags.ack == 1) tcp.dstport == 80 and tcp.flags == 0x21
- 应用层 http.request.method == "POST " smb.path contains \SERVER\SHARE
nmon
Nigel's Monitor简称nmon,是由Nigel Griffiths开发的监控Linux系统性能的常用工具。由于nmon能监控多个子系统的性能信息,所以,可以把它作为性能监控的唯一工具。通过nmon可以获取的信息有:处理器利用率、内存利用率、运行队列信息、磁盘I/O统计和网络I/O统计,页活动信息和进程指标。运行nmon,只需要通过输入感兴趣的子系统的首字母,获取相关信息。例如,获得CPU,内存、磁盘统计,首先运行nmon,然后输入c m d。nmon的一个很有用的特性是能够使用逗号分割的CVS文件保存性能统计,以便以后观察。nmon输出的CSV文件可以导入电子表格应用中,生成可视化图形报告,要使用该功能,启动nmon的时候需要带上-f选项。例如使用如下命令,让nmon生成30秒钟为频率,总时长1小时的报告。
# nmon -f -s 30 -c 120
上面的命令将把统计生成的文本文件存储在当前目录下,名字格式为
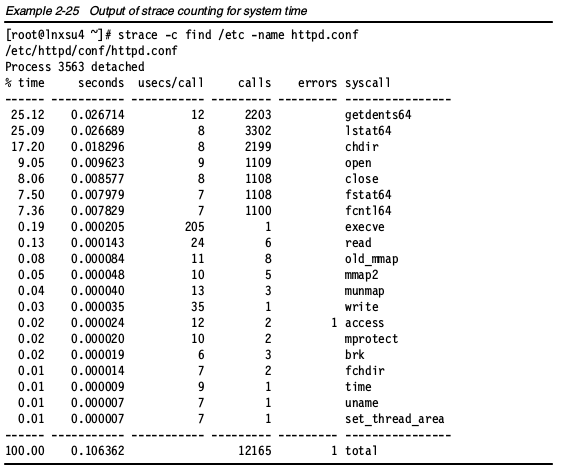
strace
strace命令会拦截和记录进程的系统调用或进程接收到的信号。这是一个有用的诊断、教学和调试工具。它在解决程序遇到的问题方面很有价值。使用时,需要指定要监控的进程ID
strace -p <pid>
下图是strace的输出实例:
注意:当对一个进程执行strace命令时,该进程的性能急剧下降。
strace还有一个有趣的用法,下面这个命令会展示,在执行一个命令是,每个系统调用在内核中所用的时间。
strace -c <command>
 如下命令获取strace的完整语法:
如下命令获取strace的完整语法:
strace -?
Proc文件系统
proc文件系统不是真实的文件系统,但是它真的十分有用。它不是存储数据的;而是提供运行内核的监控和操作接口。proc文件系统让管理员可以监控和修改运行中的内核。下图展示了一个简单的proc文件系统。大多数Linux性能工具都要依赖于/proc提供的信息。 观察这个proc文件系统,我们可以分辨出各个子目录的用途,但是由于proc目录下的大多数信息对人类来说比较难以理解,所以推荐使用类似于vmstat这类工具,以更高可读的方式展示统计数据。 注意,在不同的系统架构中,proc文件系统下的信息和布局有存在差异。
观察这个proc文件系统,我们可以分辨出各个子目录的用途,但是由于proc目录下的大多数信息对人类来说比较难以理解,所以推荐使用类似于vmstat这类工具,以更高可读的方式展示统计数据。 注意,在不同的系统架构中,proc文件系统下的信息和布局有存在差异。
- /proc目录下的文件 /proc根目录下的各种文件里面包含相关系统的统计。你可以找到Linux工具使用的信息源,例如vmstat和cpuinfo文件。
- 数字1到X 各个数字的子目录指向的是运行进程或者它们的进程ID(PID)。目录结构总是已PID 1开始,指向的是init进程,然后是系统上运行的各个PID。每个数字子目录下保存进程相关的统计信息。例如进程映射的虚拟内存。
- acpi ACPI意思是高级配置与电源接口(advanced configuration and power interface),,受到大多数现代桌面和笔记本系统支持。由于ACPI主要是PC技术,所以在服务器上通常是禁用状态。ACPI的更多信息,查看http://www.apci.info
- 总线(bus) 这个子目录包含总线子系统的信息,例如PCI总线或者系统USB接口。
- irq irq目录包含系统中断的信息。这个目录下的每个子目录代表一次中断,也可能是一个附加设备,例如网卡。在irq子目录下,你可以修改一个给定中断的CPU关联(affinity)。
- net 网络子目录下包含网络接口的原始统计数据,例如收到的多播包或接口的路由。
- scsi scsi子目录包含系统上关于SCSI子系统的信息,例如附加设备或者驱动调整。
- sys 在sys子目录下,是可调整的内核参数,例如虚拟内存管理器或者是网络栈的行为。/proc/sys这部分内容和可调优的值在“修改内核参数”一节中会详细讲解。
- tty 虚拟终端和附加的物理设备信息都包含在tty子目录中
KDE System Guard
KDE System Guard(KSysguard)是一个KDE任务管理器和性能监控器。它使用C/S(client/Server)结构,可以监控本地和远程主机。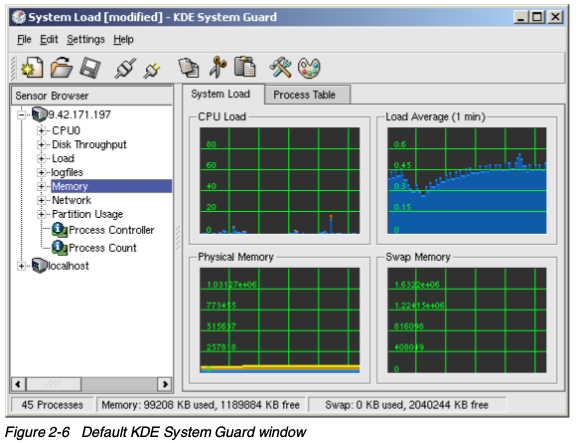 前段图像系统使用传感器取回要展示的信息。传感器可以返回简单的数值,也可以返回更加复杂的信息,比如一张表。对各类信息,提供一种或者多种展示,展示通过图表显示出来,可以各自独立的加载和保存。KSysguard主窗口包含一个菜单,一个可选工具栏,一个状态栏,传感器浏览器和工作区。第一次启动时,可以看到默认的设置:本机在传感器浏览器的localhost中,工作区中还有两个标签页。每个传感器都监视一个特定的系统值,所有的传感器都可以拖放到工作区中。有三个选项:
前段图像系统使用传感器取回要展示的信息。传感器可以返回简单的数值,也可以返回更加复杂的信息,比如一张表。对各类信息,提供一种或者多种展示,展示通过图表显示出来,可以各自独立的加载和保存。KSysguard主窗口包含一个菜单,一个可选工具栏,一个状态栏,传感器浏览器和工作区。第一次启动时,可以看到默认的设置:本机在传感器浏览器的localhost中,工作区中还有两个标签页。每个传感器都监视一个特定的系统值,所有的传感器都可以拖放到工作区中。有三个选项:
- 可以替换和删除工作区中的传感器
- 可以编辑工作表属性,增加行和列数
可以创建新的工作表,根据需求拖拽传感器到里面
工作区下图的工作区有两个标签页:系统负载,是第一次启动Ksysguard的默认视图
- 进程表
![KDE system guard传感器浏览器])(kde-system-guard-sensor-browser.png)系统负载系统负载工作表中展示死歌传感器窗口:CPU负载,平均负载(1分钟),物理内存和Swap。一个窗口中可以展示多个传感器。要查看一个窗口中监视的传感器,可以把鼠标移到图像上,就会出现相关描述。你也可以在图像上使用右键单击,然后选择属性,然后点击传感器标签,如下图。这地方展示了图像中每个颜色代表的项目。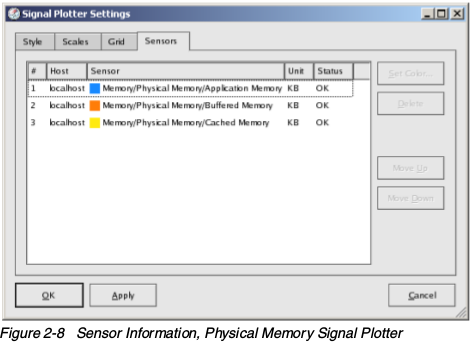
进程表点击进程表标签页,展示服务器上运行的所有进程信息。默认情况下,这张表以系统CPU使用率排序,也可以通过点击其它栏目,选择排序根据。
配置工作表对于你需要的特定环境的监控,就要用到不同的传感器。最好的办法是创建一个定制的工作表。这里将演示如何一步步创建最终的工作表。
- 通过点击 文件->新建打开一个如下窗口
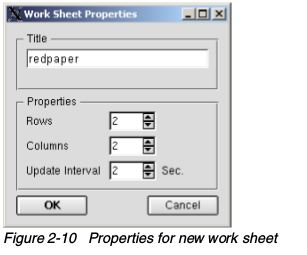
- 通过点击 文件->新建打开一个如下窗口
- 输入一个标题和行列数,这就是指定的最大窗口数目,演示中是4个窗口。完成上面的信息之后,单击确定,创建空白的工作表,如下图:
注意,更新的最快频率是2秒钟一次
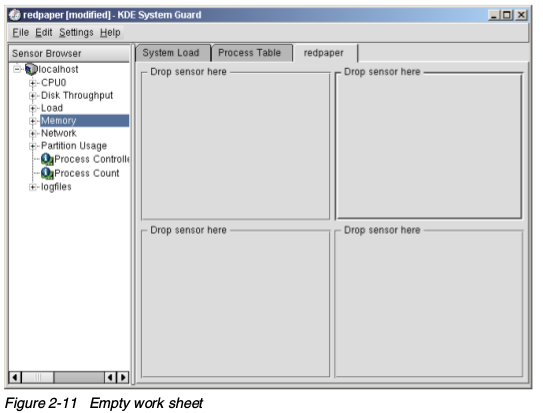
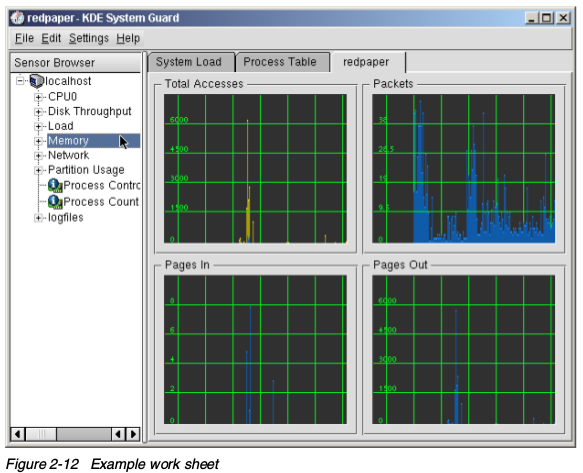
- 拖拽左边窗口的传感器到右边的空格子中,显示类型如下:
- 信号图:一次展示一个或多个传感器。如果展示多个传感器,值以不同的颜色表示。如果显示足够大,格子会显示采样的范围。默认情况下,会开启自动范围模式,最小值和最大值会自动设置。如果你想修改最小和最大值,你可以取消自动模式,并且在属性窗口的范围标签页(在图像中右键进入)中设置。
- Multimeter:把传感器的值作为数字度量,在属性窗口中,可以指定最大和最小限制。如果超出范围,会使用警告颜色显示。
- 直方图:使用dancing bar展示传感器的值,在属性窗口中,可以指定最大和最小值,以及一个最大和最小的限制。如果超出限制,以警告颜色展示。
- 传感器记录仪:这个不展示任何值,而是带上日期和时间信息记录到文件中。对每个传感器来说,你要定义目标日志文件,传感器记录的时间间隔,以及是否开启警报。
- 拖拽左边窗口的传感器到右边的空格子中,显示类型如下:
- 单击文件-> 保存,保存工作区表的修改。
在保存一个工作表的时候,它会保存到用户的家目录下,这会导致其它人不能使用你自定义的工作表
 获取更多关于KDE System Guard的信息:http://docs.kde.org/
获取更多关于KDE System Guard的信息:http://docs.kde.org/
Gnome System Monitor
虽然没有KDE Sytsem Guard强大,桌面环境提供了一个图形性能分析工具。Gnome System Monitor会把性能相关的资源图形化展示,把可能的瓶颈可视化。注意,所有的统计数据,都是实时的。长时期的性能分析应该使用其它工具。
性能管理器
Capacity Manager,是IBM System下附加于IBM Director系统管理套件,包含在IBM System x系统的Server Plus包中。Capacity Manager提供长期的性能管理,横跨多个系统和平台。Capacity Manager可以使用容量计划,帮你估计未来的容量需求。你可以把报告导出为HTML、XML和GIF文件,并且自动保存到web服务器上。IBM Director可以用在不同的操作系统平台,所以Capacity可以很容易的收集和分析各个环境的数据。Capacity Manager将会在“调优IBM System x Server性能”一节中详细讨论。要使用Capacity Manager和它的先进功能,首先你要系统上安装相应的RPM包。安装完RPM之后,在IBM Director Console中选择Capacity Manaer->Monitor Activator。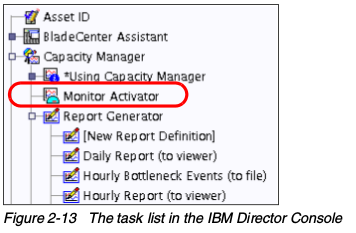 拖放Monitor Activator中一个或多个图标,将会打开窗口让你选择监控哪个子系统。Capacity Manager for Linux还不支持全部功能。系统统计只能包含性能参数的基本子集。
拖放Monitor Activator中一个或多个图标,将会打开窗口让你选择监控哪个子系统。Capacity Manager for Linux还不支持全部功能。系统统计只能包含性能参数的基本子集。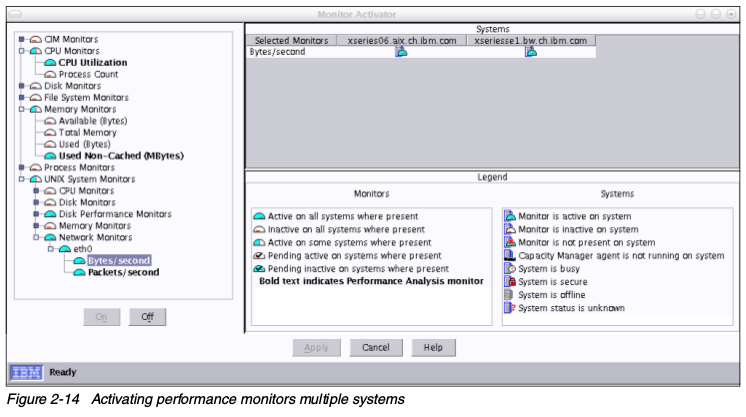 Monitor Activator窗口在右边展示了各自系统的当前状态,在左边是各类可用的系统监控。要添加一个新的监视器,选择相应的,然后点击On,在关闭Monitor Activator之后不久,修改就会生效。在上面的一步之后,IBM Director开始收集请求的性能值,并且保存在各个系统上的临时存放点。创建收集数据的报告,选择Capacity Manager->Report Generator,把他拖到你想要观察性能统计的,单个机器或者一组机器里。IBM Director会问你是直接开始收集,还是稍后执行。
Monitor Activator窗口在右边展示了各自系统的当前状态,在左边是各类可用的系统监控。要添加一个新的监视器,选择相应的,然后点击On,在关闭Monitor Activator之后不久,修改就会生效。在上面的一步之后,IBM Director开始收集请求的性能值,并且保存在各个系统上的临时存放点。创建收集数据的报告,选择Capacity Manager->Report Generator,把他拖到你想要观察性能统计的,单个机器或者一组机器里。IBM Director会问你是直接开始收集,还是稍后执行。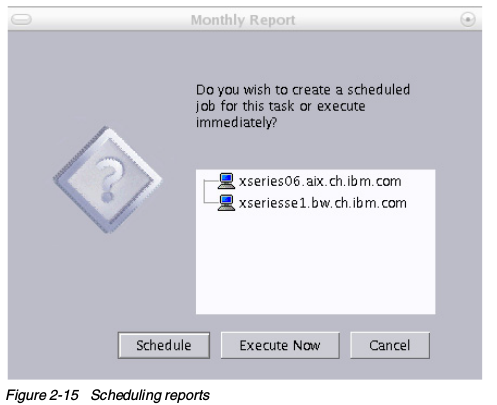 在生成环境中,最好让Capacity Manager定期生成报告。经验告诉我们,在周末生成每周报告是很有用的。你可以选择直接生成,或者按计划生成。一旦报告完成,就会保存在中心IBM Director管理服务器上,然后可以使用Report Viewer来查看。下面是Capacity Manager的报告样例。
在生成环境中,最好让Capacity Manager定期生成报告。经验告诉我们,在周末生成每周报告是很有用的。你可以选择直接生成,或者按计划生成。一旦报告完成,就会保存在中心IBM Director管理服务器上,然后可以使用Report Viewer来查看。下面是Capacity Manager的报告样例。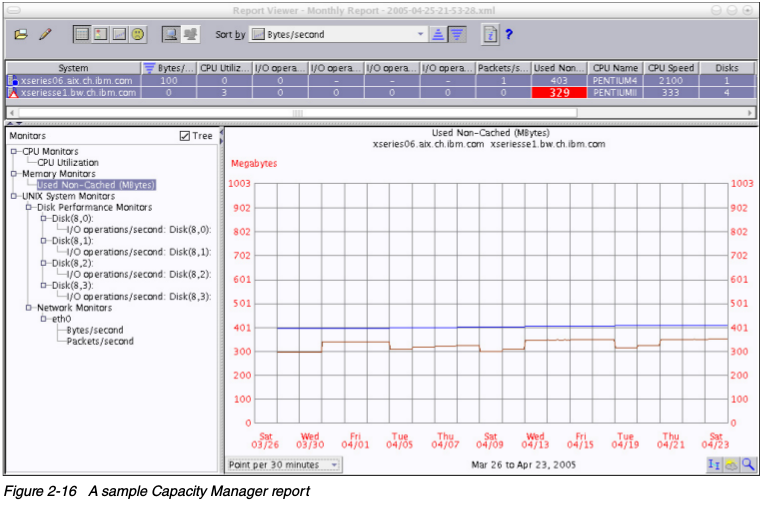 Report Viewer窗口让你可以选择不同的性能收集数据,并且关联到一个或多个选择的系统上。通过Capacity Manager获得的数据可以以HTML或XML的格式导出到Web服务器上,或者留待以后分析。
Report Viewer窗口让你可以选择不同的性能收集数据,并且关联到一个或多个选择的系统上。通过Capacity Manager获得的数据可以以HTML或XML的格式导出到Web服务器上,或者留待以后分析。
原文: https://lihz1990.gitbooks.io/transoflptg/content/02.监控和压测工具/2.3.监控工具.html
