- 应用场景(Scenario)
- 需求(Needs)
- UUID
- 多台MySQL服务器
- Twitter Snowflake
- 参考资料
如何设计一个分布式ID生成器(Distributed ID Generator),并保证ID按时间粗略有序?
应用场景(Scenario)
现实中很多业务都有生成唯一ID的需求,例如:
- 用户ID
- 微博ID
- 聊天消息ID
- 帖子ID
- 订单ID
需求(Needs)
这个ID往往会作为数据库主键,所以需要保证全局唯一。数据库会在这个字段上建立聚集索引(Clustered Index,参考 MySQL InnoDB),即该字段会影响各条数据再物理存储上的顺序。
ID还要尽可能短,节省内存,让数据库索引效率更高。基本上64位整数能够满足绝大多数的场景,但是如果能做到比64位更短那就更好了。需要根据具体业务进行分析,预估出ID的最大值,这个最大值通常比64位整数的上限小很多,于是我们可以用更少的bit表示这个ID。
查询的时候,往往有分页或者排序的需求,所以需要给每条数据添加一个时间字段,并在其上建立普通索引(Secondary Index)。但是普通索引的访问效率比聚集索引慢,如果能够让ID按照时间粗略有序,则可以省去这个时间字段。为什么不是按照时间精确有序呢?因为按照时间精确有序是做不到的,除非用一个单机算法,在分布式场景下做到精确有序性能一般很差。
这就引出了ID生成的三大核心需求:
- 全局唯一(unique)
- 按照时间粗略有序(sortable by time)
- 尽可能短
下面介绍一些常用的生成ID的方法。
UUID
用过MongoDB的人会知道,MongoDB会自动给每一条数据赋予一个唯一的ObjectId,保证不会重复,这是怎么做到的呢?实际上它用的是一种UUID算法,生成的ObjectId占12个字节,由以下几个部分组成,
- 4个字节表示的Unix timestamp,
- 3个字节表示的机器的ID
- 2个字节表示的进程ID
- 3个字节表示的计数器
UUID是一类算法的统称,具体有不同的实现。UUID的有点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,缺点是生成的ID太长,不仅占用内存,而且索引查询效率低。
多台MySQL服务器
既然MySQL可以产生自增ID,那么用多台MySQL服务器,能否组成一个高性能的分布式发号器呢? 显然可以。
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
Flickr就是这么做的,仅仅使用了两台MySQL服务器。可见这个方法虽然简单无脑,但是性能足够好。不过要注意,在MySQL中,不需要把所有ID都存下来,每台机器只需要存一个MAX_ID就可以了。这需要用到MySQL的一个REPLACE INTO特性。
这个方法跟单台数据库比,缺点是ID是不是严格递增的,只是粗略递增的。不过这个问题不大,我们的目标是粗略有序,不需要严格递增。
Twitter Snowflake
比如 Twitter 有个成熟的开源项目,就是专门生成ID的,Twitter Snowflake 。Snowflake的核心算法如下:
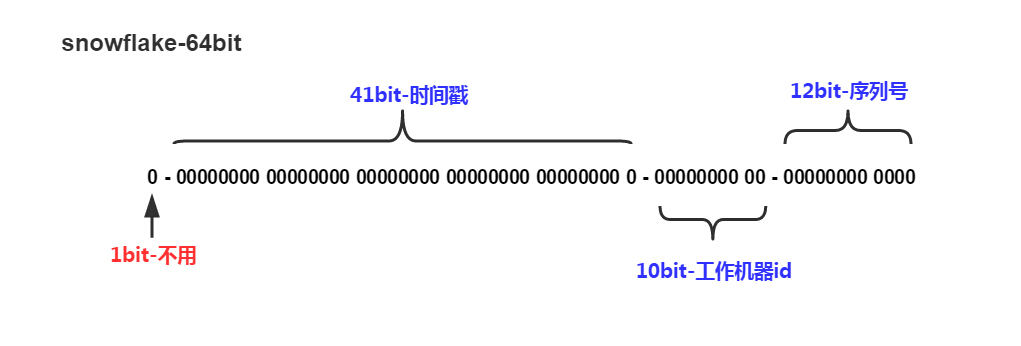
最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Instagram用了类似的方案,41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器),最低10位表示自增ID,怎么样,跟Snowflake的设计非常类似吧。这个方案用一个PostgreSQL集群代替了Twitter Snowflake 集群,优点是利用了现成的PostgreSQL,容易懂,维护方便。
有的面试官会问,如何让ID可以粗略的按照时间排序?上面的这种格式的ID,含有时间戳,且在高位,恰好满足要求。如果面试官又问,如何保证ID严格有序呢?在分布式这个场景下,是做不到的,要想高性能,只能做到粗略有序,无法保证严格有序。
参考资料
- Sharding & IDs at Instagram
- Ticket Servers: Distributed Unique Primary Keys on the Cheap
- Twitter Snowflake
- 细聊分布式ID生成方法 - 沈剑
- 服务化框架-分布式Unique ID的生成方法一览 - 江南白衣
- 生成全局唯一ID的3个思路,来自一个资深架构师的总结
