- 配置日志采集器
- 1.配置数据源
- 2.配置解析方式
- 3.配置Transformer
- 4.配置发送方式
- 5.确认runner配置
- 6.采集日志进行日志分析使用场景
配置日志采集器
logkit 可以采集各种日志(包括 nginx 等基础组件日志)至各种数据平台进行数据分析。
1.配置数据源
在配置数据源页面,您需要填好数据来源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项,一般来说,高级选项按默认设置即可。
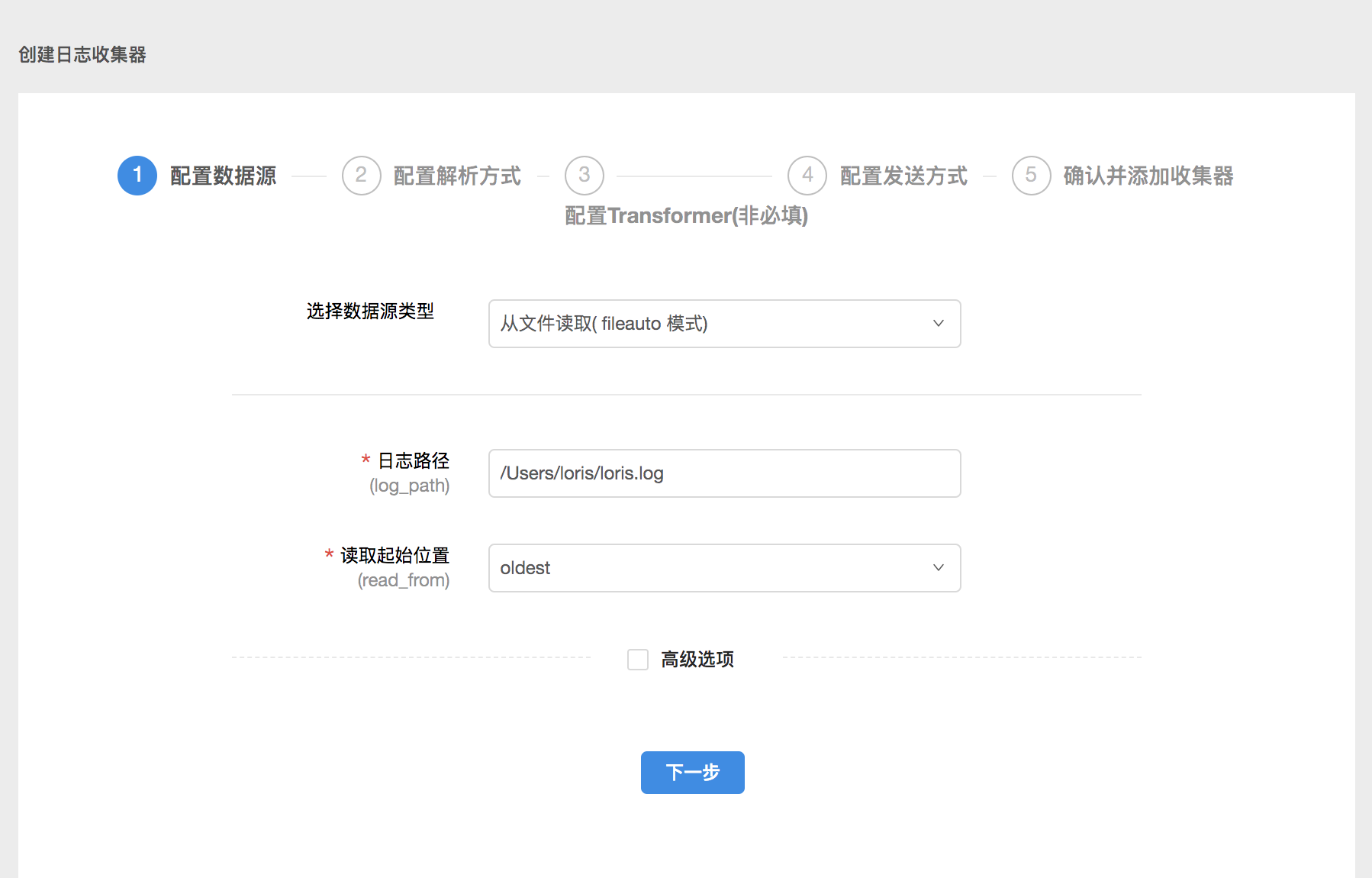
这条数据源配置的意思是从本地路径是 /Users/loris/ 的地方读取名称为 loris.log 的文件里的日志,从最早的数据读起。
2.配置解析方式
配置好数据源以后,您需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:
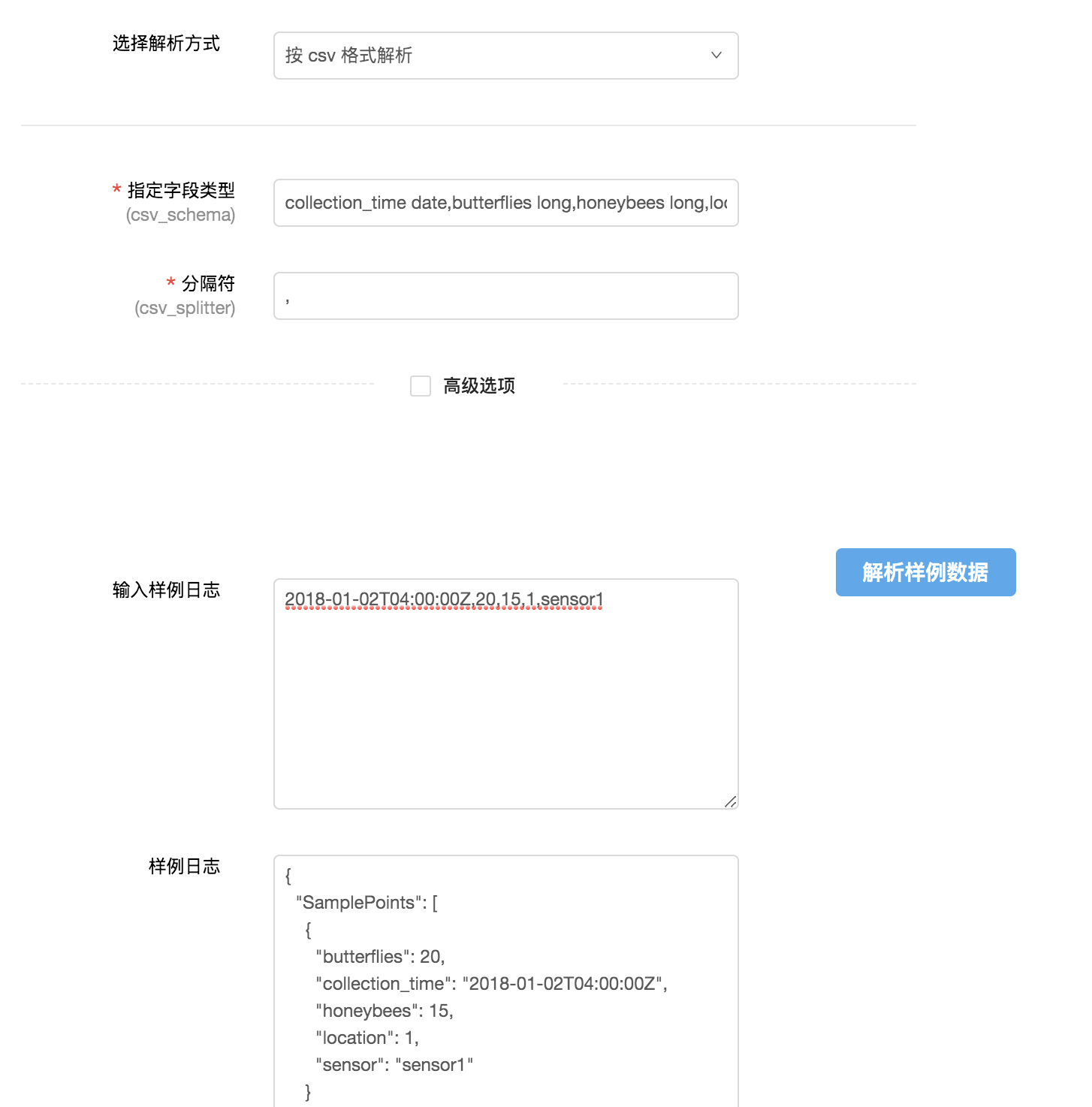
通过输入字段类型与分割符来将日志内容转化为结构化数据,方便后续在数据平台进行数据分析。
- 字段类型
您需要在这里输入详细的字段名称与类型。
- 解析样例数据
logkit 提供解析样例数据功能,即输入一行样例日志,您可以看到解析结果,来检验您的配置是否正确。
3.配置Transformer
logkit 提供 transformer 功能来满足一些更精细的字段解析需求。
以 replace transformer 为例:
通过配置 replace transformer,您可以将指定字段的某个值替换为另一个值。
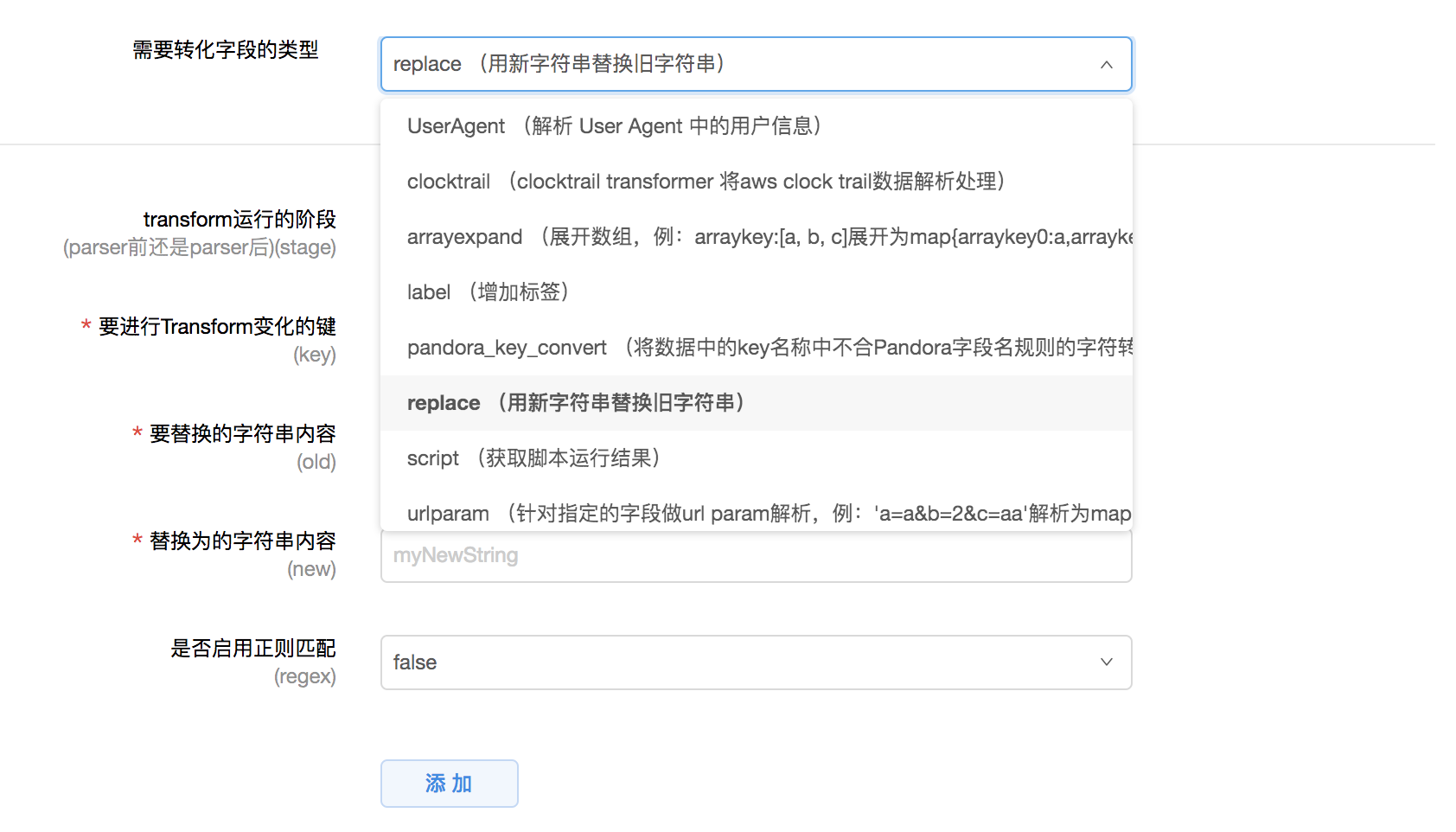
目前支持的Transformer有:
- replace transformer : 针对字段做字符串替换。
- IP transformer: 针对ip做运营商信息字段扩展。
- date transformer: 将字段解析为时间并做一些转换。
- discard transformer: 将指定字段的数据抛弃。
- split transformer: 将指定字段的数据切分为字符串数组。
- convert transformer: 按照dsl将数据进行格式转换。
- urlparam transformer: 将指定字段的数据按照url参数的格式转换为键值对。
- arrayexpand transformer: 将指定字段的数组展开并转换为键值对。
- rename transformer: 将字段名称重命名,解决不同下游系统对字段名称中特殊字符不支持的问题。
- label transformer: 添加一个带有固定值的字段到数据中,相当于加个标签。
- json transformer: 将一个符合json格式的字符串字段,反序列化为对应结构体类型。
- script transformer: 执行脚本文件并记录脚本执行结果。
- clocktrail transformer: 针对 AWS ClockTrail的数据做格式转换的Transformer,可以将ClockTrail的json格式中的 Records逐条变为数据。
- pandora_key_convert transformer: 将不符合pandora 字段类型的key字符转化为下划线。
- UserAgent transformer: 浏览器中的user agent信息解析,可以解析出包括设备、操作系统、版本号在内的多种信息。
- xml transformer: 将一个符合xml格式的字符串字段,反序列化为对应map[string]interface{}结构体类型。
如果没有字段变换需求,跳过这一步即可。
4.配置发送方式
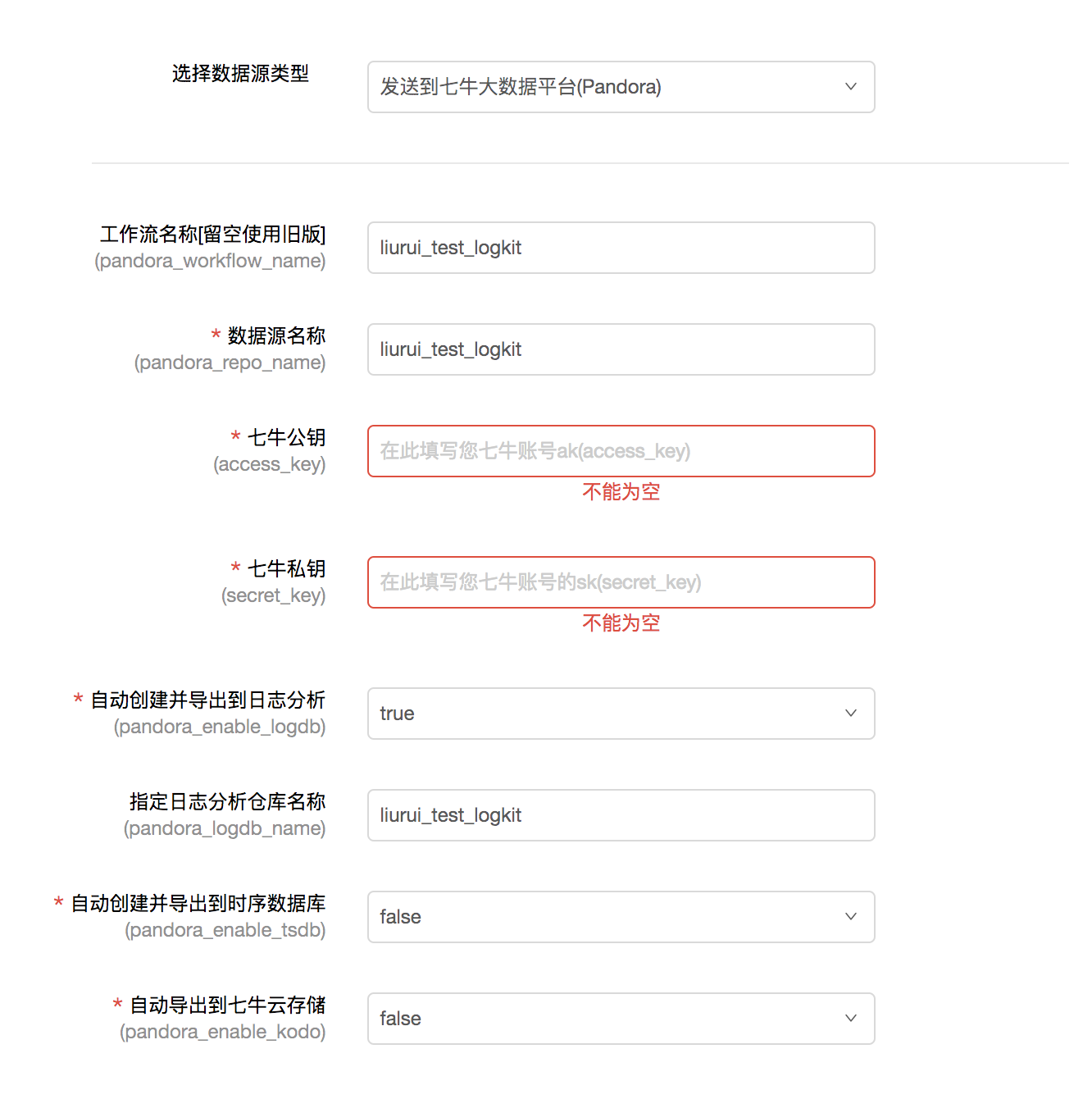
您需要选择发送的数据平台并填写相关信息来完成发送与绑定。
以发送到七牛大数据平台为例,您需要填写数据源名称、工作流名称、您的七牛账号的公钥和私钥实现数据的接收,根据需要您可以选择是否将数据导出到日志分析、时序数据库和云存储进行数据存储与分析。
5.确认runner配置
最后设置好收集数据和发送数据的时间间隔,整个runner就配置好啦!数据已经打入七牛大数据平台,您可以去七牛大数据平台进行数据计算与导出。
在配置过程中,您每一步的操作信息都会自动保存。提交之前,您可以直接返回上一步修改之前的配置信息,不用重新输入。

根据上述数据采集配置,您可以在 Logdb 根据配置中填写的日志仓库名称查询您发送的日志详情。
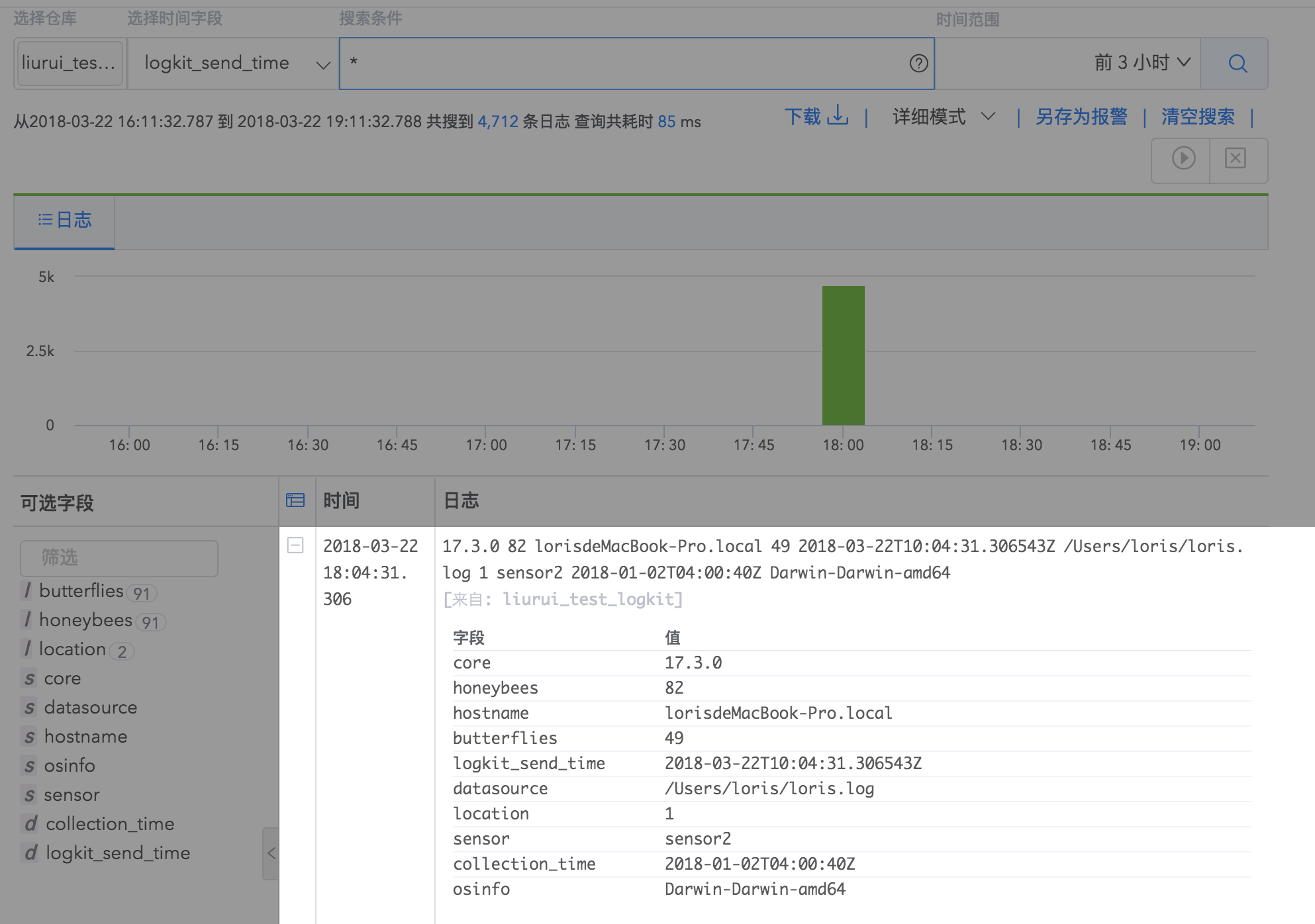
6.采集日志进行日志分析使用场景
采集Nginx日志进行日志分析并且实现实时监控。
